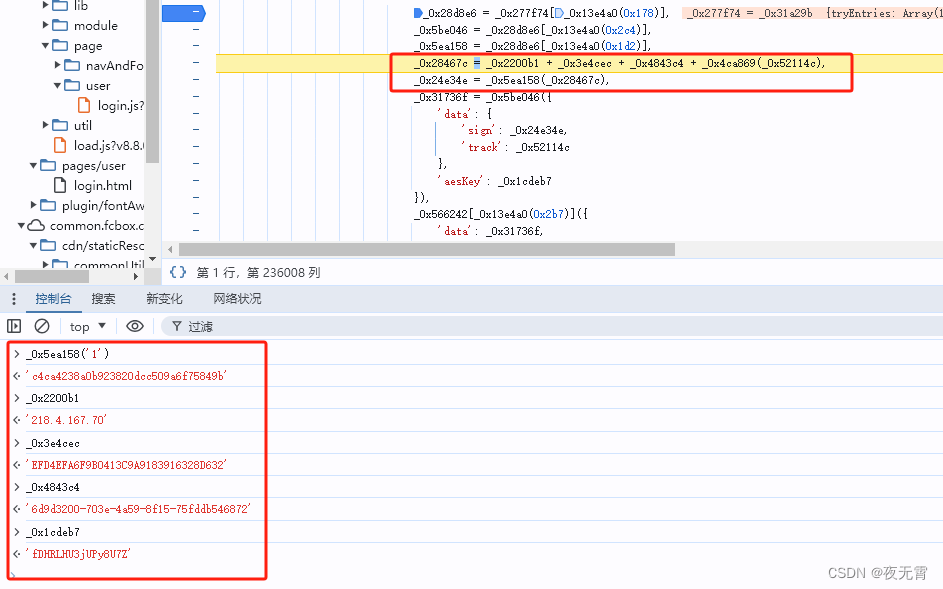
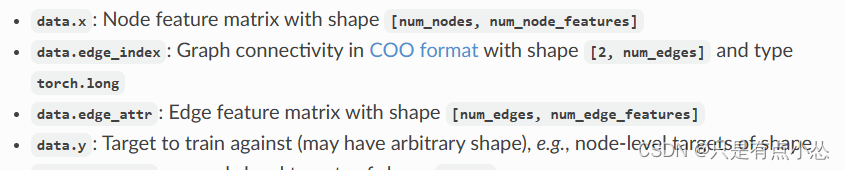
edge_index 是 PyTorch Geometric 中常用的表示图边的张量。它通常是一个形状为 [2, num_edges] 的二维张量,其中 num_edges 表示图中边的数量。每一列表示一条边,包含两个节点的索引。
- 实际上这是COO存储格式,官方文档里也有写,还有一种是邻接矩阵的存储格式,两种方式是可以互相转换的
https://pytorch-geometric.readthedocs.io/en/latest/get_started/introduction.html
edge_index[:, :10] 表示取出 edge_index 张量的前 10 列,即前 10 条边的节点索引。
在 Python 中,使用切片语法 [:,] 是一种方便的方式来选择多维数组或张量的特定部分(另外一部分Python语法知识)
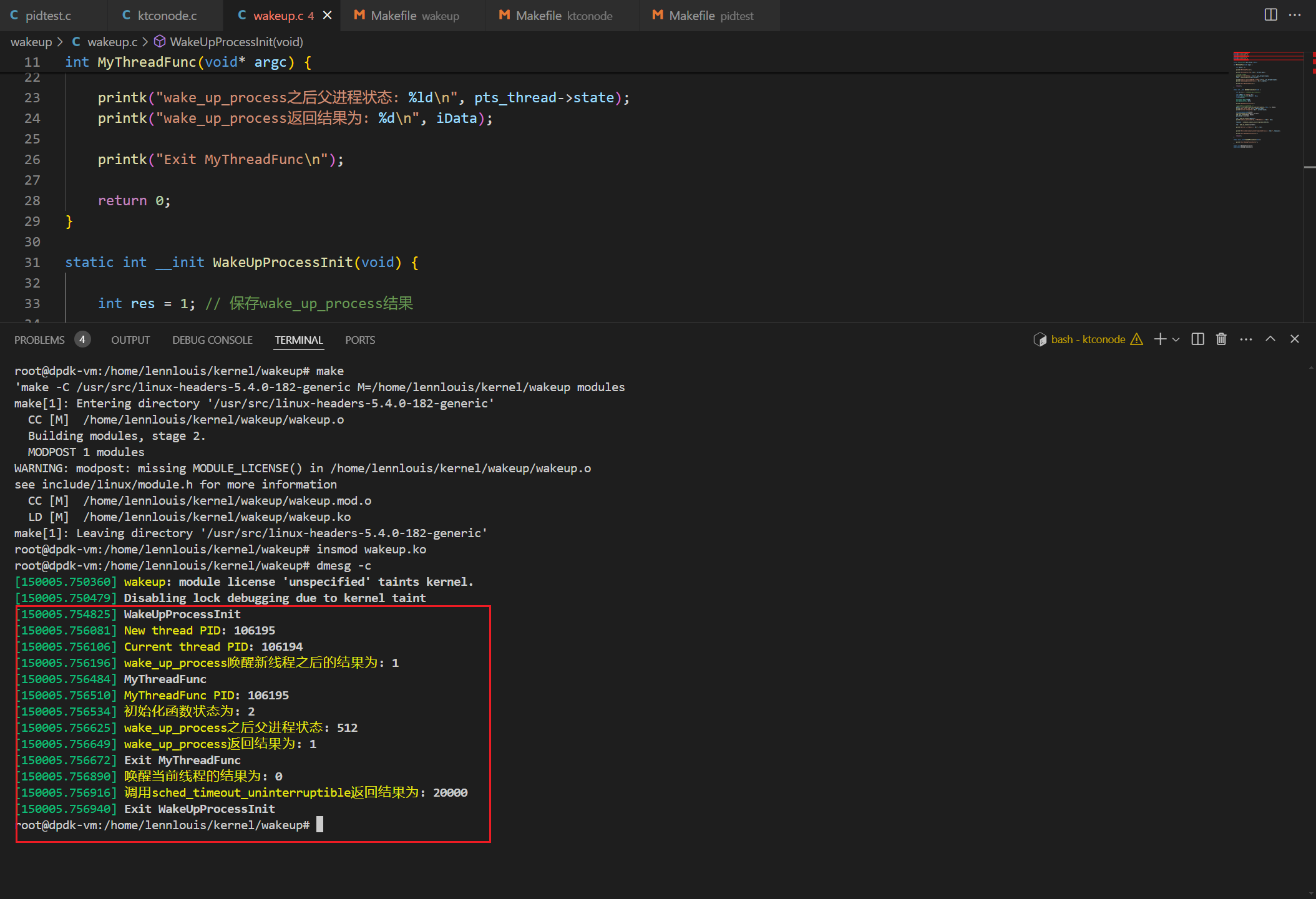
程序输出结果
Data(x=[2708, 1433], edge_index=[2, 10556], y=[2708], train_mask=[2708], val_mask=[2708], test_mask=[2708])
First 10 edges (edge_index[:, :10]):
tensor([[ 0, 0, 0, 1, 1, 1, 2, 2, 2, 2],
[ 633, 1862, 2582, 2, 652, 654, 1, 332, 1454, 1666]])
edge_index 0: tensor([ 0, 633])
edge_index 1: tensor([ 0, 1862])
edge_index 2: tensor([ 0, 2582])
edge_index 3: tensor([1, 2])
edge_index 4: tensor([ 1, 652])
edge_index 5: tensor([ 1, 654])
edge_index 6: tensor([2, 1])
edge_index 7: tensor([ 2, 332])
edge_index 8: tensor([ 2, 1454])
edge_index 9: tensor([ 2, 1666])
示例代码
假设你已经使用 PyTorch Geometric 加载了 Cora 数据集,并且 edge_index 已经被定义,以下代码展示如何查看前 10 条边的信息:
import torch
from torch_geometric.datasets import Planetoid
from torch_geometric.transforms import NormalizeFeatures
# 加载 Cora 数据集
dataset = Planetoid(root='/tmp/Cora', name='Cora', transform=NormalizeFeatures())
# 获取数据集中的第一个图
data = dataset[0]
# 打印数据集的基本信息
print(data)
# 获取边索引
edge_index = data.edge_index
# 打印前 10 条边的节点索引
print("First 10 edges (edge_index[:, :10]):")
print(edge_index[:, :10])
for i in range(10):
print(f"edge_index {i}: {edge_index[:,i]}")
示例输出
假设 edge_index 的前 10 列如下所示:
tensor([[ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9],
[ 1, 2, 0, 4, 5, 3, 7, 6, 5, 8]])
这表示:
- 第一条边是从节点 0 到节点 1。
- 第二条边是从节点 1 到节点 2。
- 第三条边是从节点 2 到节点 0。
- 第四条边是从节点 3 到节点 4。
- 第五条边是从节点 4 到节点 5。
- 第六条边是从节点 5 到节点 3。
- 第七条边是从节点 6 到节点 7。
- 第八条边是从节点 7 到节点 6。
- 第九条边是从节点 8 到节点 5。
- 第十条边是从节点 9 到节点 8。
解释
edge_index的形状为[2, num_edges],其中num_edges表示边的数量。edge_index[:, :10]表示取出前 10 条边的节点索引。- 输出的张量第一行表示每条边的起始节点,第二行表示每条边的结束节点。
通过这种方式,你可以方便地查看和理解数据集中边的表示方式。